A block-asynchronous relaxation method for graphics processing units
Summary (3 min read)
Introduction
- The authors analyze the potential of asynchronous relaxation methods on Graphics Processing Units (GPUs).
- The latest developments in hardware architectures show an enormous increase in the number of processing units (computing cores) that form one processor.
- On the other hand, numerical algorithms usually require this synchronization.
- In the following section the authors analyze the experiment results with focus on the convergence behavior and the iteration times for the different matrix systems.
B. Asynchronous Iteration Methods
- For computing the next iteration in a relaxation method, one usually requires the latest values of all components.
- The question of interest that the authors want to investigate is, what happens if this order is not adhered.
- Since the synchronization usually thwarts the overall performance, it may be true that the asynchronous iteration schemes overcompensate the inferior convergence behavior by superior scalability.
- (3) Furthermore, the following conditions can be defined to guarantee the well-posedness of the algorithm [17]: 1) The update function u(·) takes each of the values l for 1 ≤ l ≤ N infinitely often.
- The AGS method uses new values of unknowns in its subsequent updates as soon as they are computed in the same iteration, while the AJ method uses only values that are set at the beginning of an iteration.
A. Linear Systems of Equations
- In their experiments, the authors search for the approximate solutions of linear system of equations, where the respective matrices are taken from the University of Florida Matrix Collection (UFMC; see http://www.cise.ufl.edu/research/ sparse/matrices/).
- Due to the convergence properties of the iterative methods considered the experiment matrices have to be properly chosen.
- While for the Jacobi method a sufficient condition for convergence is clearly ρ(M) = ρ(I − D−1A) < 1 (i.e., the spectral radius of the iteration matrix M to be smaller than one), the convergence theory for asynchronous iteration methods is more involved (and is not the subject of this paper).
- The matrices and their descriptions are summarized in Table II, their structures can be found in Figure 1.
- The authors furthermore take the number of right-hand sides to be one for all linear systems.
B. Hardware and Software Issues
- The experiments were conducted on a heterogeneous GPU-accelerated multicore system located at the University of Tennessee, Knoxville.
- In the synchronous implementation of Gauss-Seidel on the CPU, 4 cores are used for the matrix-vector operations that can be parallelized.
- The component updates were coded in CUDA, using thread blocks of size 512.
C. An asynchronous iteration method for GPUs
- The asynchronous iteration method for GPUs that the authors propose is split into two levels.
- This is due to the design of graphics processing units and the CUDA programming language.
- For these thread blocks, a PA iteration method is used, while on each thread block, a Jacobi-like iteration method is performed.
- During the local iterations the x values used from outside the block are kept constant (equal to their values at the beginning of the local iterations).
- The shift function ν(m + 1, j) denotes the iteration shift for the component j - this can be positive or negative, depending on whether the respective other thread block already has conducted more or less iterations.
A. Stochastic impact of chaotic behavior of asynchronous iteration methods
- At this point it should be mentioned, that only the synchronous Gauss-Seidel and Jacobi methods are deterministic.
- For the asynchronous iteration method on the GPU, the results are not reproducible at all, since for every iteration run, a very unique pattern of component updates is conducted.
- It may be possible, that another component update order may result in faster or slower convergence.
- The results reported in Table IV are based on 100 simulation runs on the test matrix FV3.
- Analyzing the results, the authors observe only small variations in the convergence behavior: for 1000 iterations the relative residual is improved by 5 · 10−2, the maximal variation between the fastest and the slowest convergence rate is in the order of 10−5.
B. Convergence rate of the asynchronous iteration method
- In the next experiment, the authors analyze the convergence behavior of the asynchronous iteration method and compare it with the convergence rate of the Gauss-Seidel and Jacobi method.
- The experiment results, summarized in Figures 4, 5, 6, 7 and 9, show that for test systems CHEM97ZTZ, FV1, FV2, FV3 and TREFETHEN 2000 the synchronous Gauss-Seidel algorithm converges in considerably less iterations.
- This superior convergence behaviour is intuitively expected, since the synchronization after each component update allows the use the updated components immediately for the next update.
- Still, the authors observe for all test cases convergence rates similar to the synchronized counterpart, which is also almost doubled compared to Gauss-Seidel.
- The results for test matrix S1RMT3M1 show an example where neither of the methods is suitable for direct use.
C. Block-asynchronous iteration method
- The authors now consider a block-asynchronous iteration method which additionally performs a few Jacobi-like iterations on every subdomain.
- A motivation for this approach is hardware related – specifically, this is the fact that the additional local iterations almost come for free (as the subdomains are relatively small and the data needed largely fits into the multiprocessors’ caches).
- The case for TREFETHEN 2000 is similar – although there is improvement compared to Jacobi, the rate of convergence for async-(5) is not twice better than Gauss-Seidel, and the reason is again the structure of the local matrices .
- Due to the large overhead when performing only a small number of iterations, the average computation time per iteration decreases significantly for cases where a large number of iterations is conducted.
- Overall, the authors observe, that the average iteration time for the async-(5) method using the GPU is only a fraction of the time needed to conduct one iteration of the synchronous Gauss-Seidel on the CPU.
D. Performance of the block-asynchronous iteration method
- To analyze the performance of the block-asynchronous iteration method, the authors show in Figures 17, 18 19, 20, and 21 the average time needed for the synchronous GaussSeidel, the synchronous Jacobi and the block-asynchronous iteration method to provide a solution approximation of certain accuracy, relative to the initial residual.
- Since the convergence of the Gauss-Seidel method for S1RMT3M1 is almost negligible, and the Jacobi and the asynchronous iteration does not converge at all, the authors limit this analysis to the linear systems of equations CHEM97ZTZ, FV1, FV2, FV3 and TREFETHEN 2000.
- This is due to the fact that for these high iteration numbers the overhead triggered by memory transfer and GPU kernel call has minor impact.
- For linear equation systems with considerable off-diagonal part e.g.
- Still, due to the faster kernel execution the block-asynchronous iteration provides the solution approximation in shorter time.
V. CONCLUSIONS
- The authors developed asynchronous relaxation methods for highly parallel architectures.
- The experiments have revealed the potential of using them on GPUs.
- The absence of synchronization points enables not only to reach a high scalability, but also to efficiently use the GPU architecture.
- Nevertheless, the numerical properties of asynchronous iteration pose some restrictions on the usage.
- The presented approach could be embedded in a multigrid framework, replacing the traditional Gauss-Seidel based smoothers.
Did you find this useful? Give us your feedback
Figures (27)

Table V: Variations of the convergence behavior for 100 solver runs on FV3. 
Figure 5: Convergence for test matrix FV1 
Figure 16: Average iteration timings of CPU/GPU implementations depending on total iteration number, test matrix FV3. 
Table VII: Average iteration timings in seconds. 
Figure 17: Time to solution for CHEM97ZTZ. 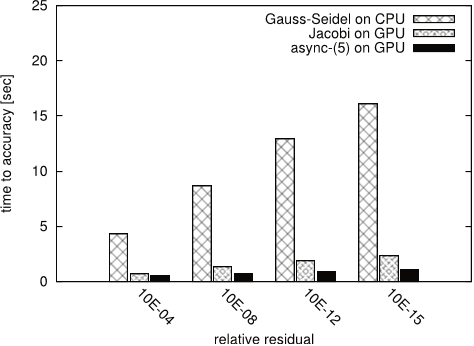
Figure 18: Time to solution for FV1. 
Figure 4: Convergence for test matrix CHEM97ZTZ 
Table IV: Variations of the convergence behavior for 100 solver runs on FV3. 
Figure 3: Statistic convergence behaviour of asynchronous iteration method. 
Figure 14: Convergence behavior of async(5) for test matrix S1RMT3M1 
Figure 13: Convergence behavior of async-(5) for test matrix FV3 
Figure 15: Convergence behavior of async-(5) for test matrix TREFETHEN 2000 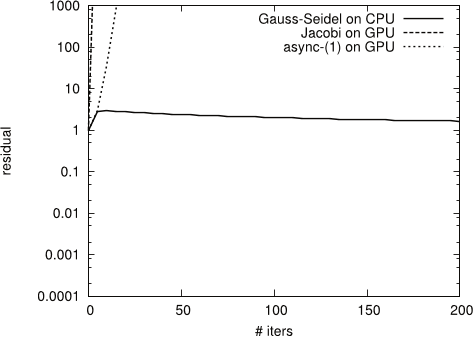
Figure 8: Convergence for test matrix S1RMT3M1 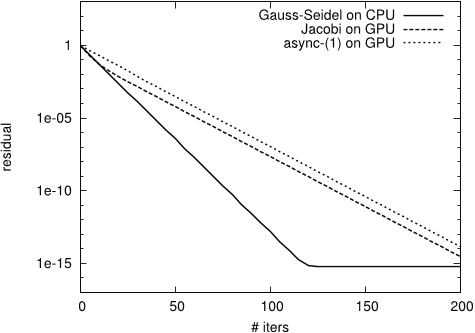
Figure 6: Convergence for test matrix FV2 
Figure 7: Convergence for test matrix FV3 
Figure 9: Convergence for test matrix TREFETHEN 2000 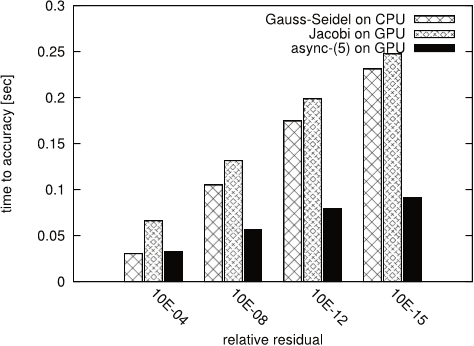
Figure 21: Time to solution for TREFETHEN 2000. 
Figure 19: Time to solution for FV2. 
Figure 20: Time to solution for FV3. 
Table VI: Overhead to total execution time by adding local iterations, matrix FV3. 
Figure 11: Convergence behavior of async-(5) for test matrix FV1





















Citations
References
13,484 citations
"A block-asynchronous relaxation met..." refers methods in this paper
...For example, when solving linear systems of equations with iterative methods like the Conjugate Gradient or GMRES, the parallelism is usually limited to the matrix-vector and the vector-vector operations (with synchronization required between them) [4] [5] [6]....
[...]
10,907 citations
2,531 citations
"A block-asynchronous relaxation met..." refers methods in this paper
...For some algorithms, e.g. Gauss-Seidel [7], even the already computed values of the current iteration step are used....
[...]
...Also, methods that are based on component-wise updates like Jacobi or Gauss- Seidel have synchronization between the iteration steps [7], [8]: no component is updated twice (or more) before all other components are updated....
[...]
736 citations
"A block-asynchronous relaxation met..." refers methods in this paper
...The reason for this varies from various physical limitations to energy minimization considerations that are at odds with further scaling up of processor' frequencies – the basic acceleration method used in the architecture designs for the last decades [1]....
[...]
539 citations