A block-asynchronous relaxation method for graphics processing units
Reads0
Chats0
TLDR
This paper develops asynchronous iteration algorithms in CUDA and compares them with parallel implementations of synchronous relaxation methods on CPU- or GPU-based systems and identifies the high potential of the asynchronous methods for Exascale computing.About:
This article is published in Journal of Parallel and Distributed Computing.The article was published on 2013-12-01 and is currently open access. It has received 28 citations till now. The article focuses on the topics: Asynchronous communication & CUDA.read more
Figures

Table V: Variations of the convergence behavior for 100 solver runs on FV3. 
Figure 5: Convergence for test matrix FV1 
Figure 16: Average iteration timings of CPU/GPU implementations depending on total iteration number, test matrix FV3. 
Table VII: Average iteration timings in seconds. 
Figure 17: Time to solution for CHEM97ZTZ. 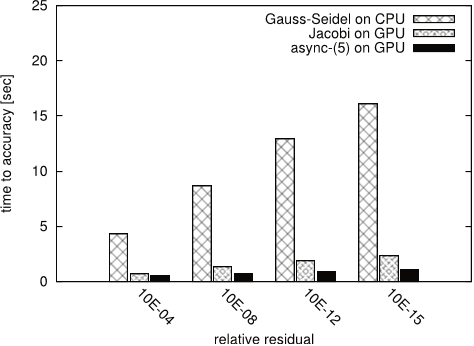
Figure 18: Time to solution for FV1.






Citations
More filters
Proceedings ArticleDOI
Self-stabilizing iterative solvers
Piyush Sao,Richard Vuduc +1 more
TL;DR: It is shown how to use the idea of self-stabilization, which originates in the context of distributed control, to make fault-tolerant iterative solvers, and has promise to become a useful tool for constructing resilient solvers more generally.
Book ChapterDOI
Iterative Sparse Triangular Solves for Preconditioning
TL;DR: This work proposes using an iterative approach for solving sparse triangular systems when an approximation is suitable, and demonstrates the performance gains that this approach can have on GPUs in the context of solving sparse linear systems with a preconditioned Krylov subspace method.
Journal ArticleDOI
Automatic Recognition of Acute Myelogenous Leukemia in Blood Microscopic Images Using K-means Clustering and Support Vector Machine.
TL;DR: The results show that the proposed algorithm has achieved an acceptable performance for diagnosis of AML and its common subtypes and can be used as an assistant diagnostic tool for pathologists.
Book ChapterDOI
Asynchronous Iterative Algorithm for Computing Incomplete Factorizations on GPUs
TL;DR: This paper presents a GPU implementation of an asynchronous iterative algorithm for computing incomplete factorizations that considers several non-traditional techniques that can be important for asynchronous algorithms to optimize convergence and data locality.
Journal ArticleDOI
Linear Algebra Software for Large-Scale Accelerated Multicore Computing
Ahmad Abdelfattah,Hartwig Anzt,Jack Dongarra,Mark Gates,Azzam Haidar,Jakub Kurzak,Piotr Luszczek,Stanimire Tomov,Ichitaro Yamazaki,Asim YarKhan +9 more
TL;DR: The state-of-the-art design and implementation practices for the acceleration of the predominant linear algebra algorithms on large-scale accelerated multicore systems are presented and the development of innovativelinear algebra algorithms using three technologies – mixed precision arithmetic, batched operations, and asynchronous iterations – that are currently of high interest for accelerated multicores systems are emphasized.
References
More filters
Book
Vector Calculus, Linear Algebra, and Differential Forms: A Unified Approach
TL;DR: In this article, the authors propose a vector calculus with higher partial derivatives, Quadratic forms, and Manifolds, which is based on the Vector Calculus of Vector.
Journal ArticleDOI
Distributed Asynchronous Relaxation Methods for Linear Network Flow Problems
TL;DR: Finite convergence of a totally asynchronous (chaotic), distributed version of the massively parallelizable algorithm in which some processors compute faster than others, some processors communicate faster thanOthers, and there can be arbitrarily large communication delays is shown.
Asynchronous weighted additive schwarz methods
TL;DR: A class of asynchronous Schwarz methods for the parallel solution of nonsingular linear systems of the form is investigated, including an asynchronous algebraic Schwarz method as well as asynchronous multisplitting, which have been revived in the last decade as the basis for domain decomposition methods.
Journal ArticleDOI
A unified proof for the convergence of Jacobi and Gauss-Seidel methods
TL;DR: A new unified proof for the convergence of both the Jacobi and the Gauss–Seidel methods for solving systems of linear equations under the criterion of either (a) strict diagonal dominance of the matrix, or (b) diagonal dominance and irreducibility of the Matrix.
Proceedings ArticleDOI
Parallel Dense Gauss-Seidel Algorithm on Many-Core Processors
TL;DR: This paper proposes to study several parallelization schemes for fully-coupled systems, unable to be parallelized by existing methods, taking advantage of recent many-cores architectures offering fast synchronization primitives.