A block-asynchronous relaxation method for graphics processing units
Reads0
Chats0
TLDR
This paper develops asynchronous iteration algorithms in CUDA and compares them with parallel implementations of synchronous relaxation methods on CPU- or GPU-based systems and identifies the high potential of the asynchronous methods for Exascale computing.About:
This article is published in Journal of Parallel and Distributed Computing.The article was published on 2013-12-01 and is currently open access. It has received 28 citations till now. The article focuses on the topics: Asynchronous communication & CUDA.read more
Figures

Table V: Variations of the convergence behavior for 100 solver runs on FV3. 
Figure 5: Convergence for test matrix FV1 
Figure 16: Average iteration timings of CPU/GPU implementations depending on total iteration number, test matrix FV3. 
Table VII: Average iteration timings in seconds. 
Figure 17: Time to solution for CHEM97ZTZ. 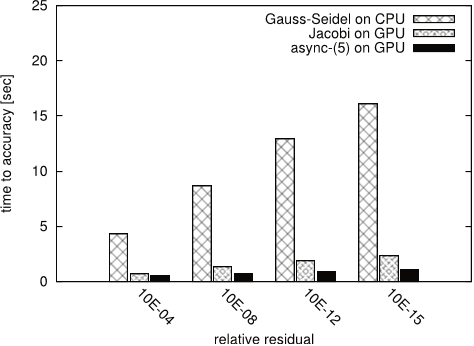
Figure 18: Time to solution for FV1.






Citations
More filters
Proceedings ArticleDOI
Self-stabilizing iterative solvers
Piyush Sao,Richard Vuduc +1 more
TL;DR: It is shown how to use the idea of self-stabilization, which originates in the context of distributed control, to make fault-tolerant iterative solvers, and has promise to become a useful tool for constructing resilient solvers more generally.
Book ChapterDOI
Iterative Sparse Triangular Solves for Preconditioning
TL;DR: This work proposes using an iterative approach for solving sparse triangular systems when an approximation is suitable, and demonstrates the performance gains that this approach can have on GPUs in the context of solving sparse linear systems with a preconditioned Krylov subspace method.
Journal ArticleDOI
Automatic Recognition of Acute Myelogenous Leukemia in Blood Microscopic Images Using K-means Clustering and Support Vector Machine.
TL;DR: The results show that the proposed algorithm has achieved an acceptable performance for diagnosis of AML and its common subtypes and can be used as an assistant diagnostic tool for pathologists.
Book ChapterDOI
Asynchronous Iterative Algorithm for Computing Incomplete Factorizations on GPUs
TL;DR: This paper presents a GPU implementation of an asynchronous iterative algorithm for computing incomplete factorizations that considers several non-traditional techniques that can be important for asynchronous algorithms to optimize convergence and data locality.
Journal ArticleDOI
Linear Algebra Software for Large-Scale Accelerated Multicore Computing
Ahmad Abdelfattah,Hartwig Anzt,Jack Dongarra,Mark Gates,Azzam Haidar,Jakub Kurzak,Piotr Luszczek,Stanimire Tomov,Ichitaro Yamazaki,Asim YarKhan +9 more
TL;DR: The state-of-the-art design and implementation practices for the acceleration of the predominant linear algebra algorithms on large-scale accelerated multicore systems are presented and the development of innovativelinear algebra algorithms using three technologies – mixed precision arithmetic, batched operations, and asynchronous iterations – that are currently of high interest for accelerated multicores systems are emphasized.
References
More filters
Book ChapterDOI
Scaling Algebraic Multigrid Solvers: On the Road to Exascale
Allison H. Baker,Robert D. Falgout,Todd Gamblin,Tzanio V. Kolev,Martin Schulz,Ulrike Meier Yang +5 more
TL;DR: This work discusses the experiences and describes the techniques used to overcome scalability challenges for AMG on hybrid architectures in preparation for exascale.
Journal ArticleDOI
On the use of relaxation parameters in hybrid smoothers
TL;DR: The use of relaxation parameters in hybrid smoothers within algebraic multigrid (AMG) is analysed both theoretically and practically and a procedure to automatically determine outer relaxation parameters for symmetric positive definite smoothers is described.
Journal ArticleDOI
Sufficient conditions for the convergence of asynchronous iterations
Aydin Üresin,Michel Dubois +1 more
TL;DR: A multitasked implementation of the scene-labeling algorithm in a distributed global memory system is detailed, and no synchronization nor critical sections are necessary to enforce correctness of execution.
Journal ArticleDOI
Block and asynchronous two-stage methods for mildly nonlinear systems
TL;DR: Both synchronous and asynchronous versions of the asynchronous method when applied to linear systems are analyzed, and both pointwise and blockwise convergence theorems provided.
Journal ArticleDOI
Algorithm-based fault tolerance for dense matrix factorizations
TL;DR: Dense matrix factorizations, such as LU, Cholesky and QR, are widely used for scientific applications that require solving systems of linear equations, eigenvalues and linear least squares problems.