A block-asynchronous relaxation method for graphics processing units
01 Dec 2013-Journal of Parallel and Distributed Computing (Academic Press, Inc.)-Vol. 73, Iss: 12, pp 1613-1626
TL;DR: This paper develops asynchronous iteration algorithms in CUDA and compares them with parallel implementations of synchronous relaxation methods on CPU- or GPU-based systems and identifies the high potential of the asynchronous methods for Exascale computing.
About: This article is published in Journal of Parallel and Distributed Computing.The article was published on 2013-12-01 and is currently open access. It has received 28 citations till now. The article focuses on the topics: Asynchronous communication & CUDA.
Summary (3 min read)
Jump to: [Introduction] – [B. Asynchronous Iteration Methods] – [A. Linear Systems of Equations] – [B. Hardware and Software Issues] – [C. An asynchronous iteration method for GPUs] – [A. Stochastic impact of chaotic behavior of asynchronous iteration methods] – [B. Convergence rate of the asynchronous iteration method] – [C. Block-asynchronous iteration method] – [D. Performance of the block-asynchronous iteration method] and [V. CONCLUSIONS]
Introduction
- The authors analyze the potential of asynchronous relaxation methods on Graphics Processing Units (GPUs).
- The latest developments in hardware architectures show an enormous increase in the number of processing units (computing cores) that form one processor.
- On the other hand, numerical algorithms usually require this synchronization.
- In the following section the authors analyze the experiment results with focus on the convergence behavior and the iteration times for the different matrix systems.
B. Asynchronous Iteration Methods
- For computing the next iteration in a relaxation method, one usually requires the latest values of all components.
- The question of interest that the authors want to investigate is, what happens if this order is not adhered.
- Since the synchronization usually thwarts the overall performance, it may be true that the asynchronous iteration schemes overcompensate the inferior convergence behavior by superior scalability.
- (3) Furthermore, the following conditions can be defined to guarantee the well-posedness of the algorithm [17]: 1) The update function u(·) takes each of the values l for 1 ≤ l ≤ N infinitely often.
- The AGS method uses new values of unknowns in its subsequent updates as soon as they are computed in the same iteration, while the AJ method uses only values that are set at the beginning of an iteration.
A. Linear Systems of Equations
- In their experiments, the authors search for the approximate solutions of linear system of equations, where the respective matrices are taken from the University of Florida Matrix Collection (UFMC; see http://www.cise.ufl.edu/research/ sparse/matrices/).
- Due to the convergence properties of the iterative methods considered the experiment matrices have to be properly chosen.
- While for the Jacobi method a sufficient condition for convergence is clearly ρ(M) = ρ(I − D−1A) < 1 (i.e., the spectral radius of the iteration matrix M to be smaller than one), the convergence theory for asynchronous iteration methods is more involved (and is not the subject of this paper).
- The matrices and their descriptions are summarized in Table II, their structures can be found in Figure 1.
- The authors furthermore take the number of right-hand sides to be one for all linear systems.
B. Hardware and Software Issues
- The experiments were conducted on a heterogeneous GPU-accelerated multicore system located at the University of Tennessee, Knoxville.
- In the synchronous implementation of Gauss-Seidel on the CPU, 4 cores are used for the matrix-vector operations that can be parallelized.
- The component updates were coded in CUDA, using thread blocks of size 512.
C. An asynchronous iteration method for GPUs
- The asynchronous iteration method for GPUs that the authors propose is split into two levels.
- This is due to the design of graphics processing units and the CUDA programming language.
- For these thread blocks, a PA iteration method is used, while on each thread block, a Jacobi-like iteration method is performed.
- During the local iterations the x values used from outside the block are kept constant (equal to their values at the beginning of the local iterations).
- The shift function ν(m + 1, j) denotes the iteration shift for the component j - this can be positive or negative, depending on whether the respective other thread block already has conducted more or less iterations.
A. Stochastic impact of chaotic behavior of asynchronous iteration methods
- At this point it should be mentioned, that only the synchronous Gauss-Seidel and Jacobi methods are deterministic.
- For the asynchronous iteration method on the GPU, the results are not reproducible at all, since for every iteration run, a very unique pattern of component updates is conducted.
- It may be possible, that another component update order may result in faster or slower convergence.
- The results reported in Table IV are based on 100 simulation runs on the test matrix FV3.
- Analyzing the results, the authors observe only small variations in the convergence behavior: for 1000 iterations the relative residual is improved by 5 · 10−2, the maximal variation between the fastest and the slowest convergence rate is in the order of 10−5.
B. Convergence rate of the asynchronous iteration method
- In the next experiment, the authors analyze the convergence behavior of the asynchronous iteration method and compare it with the convergence rate of the Gauss-Seidel and Jacobi method.
- The experiment results, summarized in Figures 4, 5, 6, 7 and 9, show that for test systems CHEM97ZTZ, FV1, FV2, FV3 and TREFETHEN 2000 the synchronous Gauss-Seidel algorithm converges in considerably less iterations.
- This superior convergence behaviour is intuitively expected, since the synchronization after each component update allows the use the updated components immediately for the next update.
- Still, the authors observe for all test cases convergence rates similar to the synchronized counterpart, which is also almost doubled compared to Gauss-Seidel.
- The results for test matrix S1RMT3M1 show an example where neither of the methods is suitable for direct use.
C. Block-asynchronous iteration method
- The authors now consider a block-asynchronous iteration method which additionally performs a few Jacobi-like iterations on every subdomain.
- A motivation for this approach is hardware related – specifically, this is the fact that the additional local iterations almost come for free (as the subdomains are relatively small and the data needed largely fits into the multiprocessors’ caches).
- The case for TREFETHEN 2000 is similar – although there is improvement compared to Jacobi, the rate of convergence for async-(5) is not twice better than Gauss-Seidel, and the reason is again the structure of the local matrices .
- Due to the large overhead when performing only a small number of iterations, the average computation time per iteration decreases significantly for cases where a large number of iterations is conducted.
- Overall, the authors observe, that the average iteration time for the async-(5) method using the GPU is only a fraction of the time needed to conduct one iteration of the synchronous Gauss-Seidel on the CPU.
D. Performance of the block-asynchronous iteration method
- To analyze the performance of the block-asynchronous iteration method, the authors show in Figures 17, 18 19, 20, and 21 the average time needed for the synchronous GaussSeidel, the synchronous Jacobi and the block-asynchronous iteration method to provide a solution approximation of certain accuracy, relative to the initial residual.
- Since the convergence of the Gauss-Seidel method for S1RMT3M1 is almost negligible, and the Jacobi and the asynchronous iteration does not converge at all, the authors limit this analysis to the linear systems of equations CHEM97ZTZ, FV1, FV2, FV3 and TREFETHEN 2000.
- This is due to the fact that for these high iteration numbers the overhead triggered by memory transfer and GPU kernel call has minor impact.
- For linear equation systems with considerable off-diagonal part e.g.
- Still, due to the faster kernel execution the block-asynchronous iteration provides the solution approximation in shorter time.
V. CONCLUSIONS
- The authors developed asynchronous relaxation methods for highly parallel architectures.
- The experiments have revealed the potential of using them on GPUs.
- The absence of synchronization points enables not only to reach a high scalability, but also to efficiently use the GPU architecture.
- Nevertheless, the numerical properties of asynchronous iteration pose some restrictions on the usage.
- The presented approach could be embedded in a multigrid framework, replacing the traditional Gauss-Seidel based smoothers.
Did you find this useful? Give us your feedback
Figures (27)

Table V: Variations of the convergence behavior for 100 solver runs on FV3. 
Figure 5: Convergence for test matrix FV1 
Figure 16: Average iteration timings of CPU/GPU implementations depending on total iteration number, test matrix FV3. 
Table VII: Average iteration timings in seconds. 
Figure 17: Time to solution for CHEM97ZTZ. 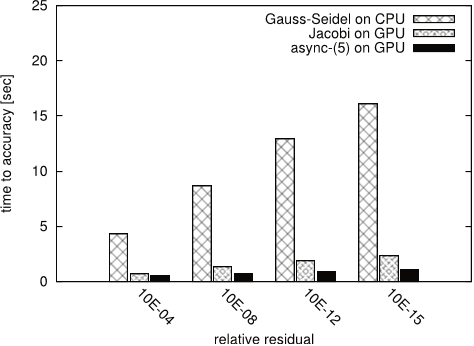
Figure 18: Time to solution for FV1. 
Figure 4: Convergence for test matrix CHEM97ZTZ 
Table IV: Variations of the convergence behavior for 100 solver runs on FV3. 
Figure 3: Statistic convergence behaviour of asynchronous iteration method. 
Figure 14: Convergence behavior of async(5) for test matrix S1RMT3M1 
Figure 13: Convergence behavior of async-(5) for test matrix FV3 
Figure 15: Convergence behavior of async-(5) for test matrix TREFETHEN 2000 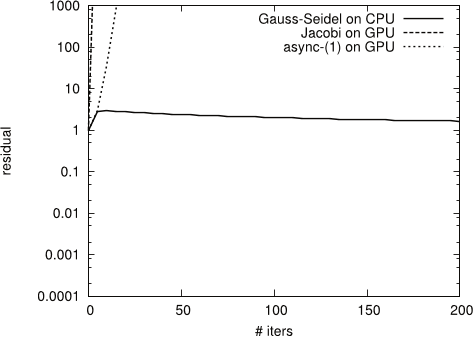
Figure 8: Convergence for test matrix S1RMT3M1 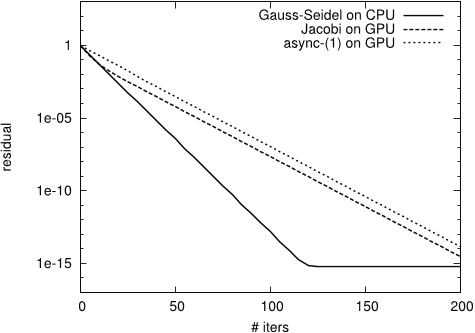
Figure 6: Convergence for test matrix FV2 
Figure 7: Convergence for test matrix FV3 
Figure 9: Convergence for test matrix TREFETHEN 2000 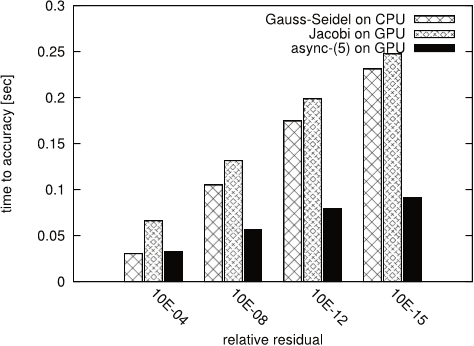
Figure 21: Time to solution for TREFETHEN 2000. 
Figure 19: Time to solution for FV2. 
Figure 20: Time to solution for FV3. 
Table VI: Overhead to total execution time by adding local iterations, matrix FV3. 
Figure 11: Convergence behavior of async-(5) for test matrix FV1





















Citations
More filters
17 Nov 2013
TL;DR: It is shown how to use the idea of self-stabilization, which originates in the context of distributed control, to make fault-tolerant iterative solvers, and has promise to become a useful tool for constructing resilient solvers more generally.
Abstract: We show how to use the idea of self-stabilization, which originates in the context of distributed control, to make fault-tolerant iterative solvers. Generally, a self-stabilizing system is one that, starting from an arbitrary state (valid or invalid), reaches a valid state within a finite number of steps. This property imbues the system with a natural means of tolerating transient faults. We give two proof-of-concept examples of self-stabilizing iterative linear solvers: one for steepest descent (SD) and one for conjugate gradients (CG). Our self-stabilized versions of SD and CG require small amounts of fault-detection, e.g., we may check only for NaNs and infinities. We test our approach experimentally by analyzing its convergence and overhead for different types and rates of faults. Beyond the specific findings of this paper, we believe self-stabilization has promise to become a useful tool for constructing resilient solvers more generally.
102 citations
24 Aug 2015
TL;DR: This work proposes using an iterative approach for solving sparse triangular systems when an approximation is suitable, and demonstrates the performance gains that this approach can have on GPUs in the context of solving sparse linear systems with a preconditioned Krylov subspace method.
Abstract: Sparse triangular solvers are typically parallelized using level-scheduling techniques, but parallel efficiency is poor on high-throughput architectures like GPUs. We propose using an iterative approach for solving sparse triangular systems when an approximation is suitable. This approach will not work for all problems, but can be successful for sparse triangular matrices arising from incomplete factorizations, where an approximate solution is acceptable. We demonstrate the performance gains that this approach can have on GPUs in the context of solving sparse linear systems with a preconditioned Krylov subspace method. We also illustrate the effect of using asynchronous iterations.
73 citations
TL;DR: The results show that the proposed algorithm has achieved an acceptable performance for diagnosis of AML and its common subtypes and can be used as an assistant diagnostic tool for pathologists.
Abstract: Acute myelogenous leukemia (AML) is a subtype of acute leukemia, which is characterized by the accumulation of myeloid blasts in the bone marrow. Careful microscopic examination of stained blood smear or bone marrow aspirate is still the most significant diagnostic methodology for initial AML screening and considered as the first step toward diagnosis. It is time-consuming and due to the elusive nature of the signs and symptoms of AML; wrong diagnosis may occur by pathologists. Therefore, the need for automation of leukemia detection has arisen. In this paper, an automatic technique for identification and detection of AML and its prevalent subtypes, i.e., M2-M5 is presented. At first, microscopic images are acquired from blood smears of patients with AML and normal cases. After applying image preprocessing, color segmentation strategy is applied for segmenting white blood cells from other blood components and then discriminative features, i.e., irregularity, nucleus-cytoplasm ratio, Hausdorff dimension, shape, color, and texture features are extracted from the entire nucleus in the whole images containing multiple nuclei. Images are classified to cancerous and noncancerous images by binary support vector machine (SVM) classifier with 10-fold cross validation technique. Classifier performance is evaluated by three parameters, i.e., sensitivity, specificity, and accuracy. Cancerous images are also classified into their prevalent subtypes by multi-SVM classifier. The results show that the proposed algorithm has achieved an acceptable performance for diagnosis of AML and its common subtypes. Therefore, it can be used as an assistant diagnostic tool for pathologists.
52 citations
12 Jul 2015
TL;DR: This paper presents a GPU implementation of an asynchronous iterative algorithm for computing incomplete factorizations that considers several non-traditional techniques that can be important for asynchronous algorithms to optimize convergence and data locality.
Abstract: This paper presents a GPU implementation of an asynchronous iterative algorithm for computing incomplete factorizations. Asynchronous algorithms, with their ability to tolerate memory latency, form an important class of algorithms for modern computer architectures. Our GPU implementation considers several non-traditional techniques that can be important for asynchronous algorithms to optimize convergence and data locality. These techniques include controlling the order in which variables are updated by controlling the order of execution of thread blocks, taking advantage of cache reuse between thread blocks, and managing the amount of parallelism to control the convergence of the algorithm.
39 citations
TL;DR: The state-of-the-art design and implementation practices for the acceleration of the predominant linear algebra algorithms on large-scale accelerated multicore systems are presented and the development of innovativelinear algebra algorithms using three technologies – mixed precision arithmetic, batched operations, and asynchronous iterations – that are currently of high interest for accelerated multicores systems are emphasized.
Abstract: Many crucial scientific computing applications, ranging from national security to medical advances, rely on high-performance linear algebra algorithms and technologies, underscoring their importance and broad impact Here we present the state-of-the-art design and implementation practices for the acceleration of the predominant linear algebra algorithms on large-scale accelerated multicore systems Examples are given with fundamental dense linear algebra algorithms – from the LU, QR, Cholesky, and LDLT factorizations needed for solving linear systems of equations, to eigenvalue and singular value decomposition (SVD) problems The implementations presented are readily available via the open-source PLASMA and MAGMA libraries, which represent the next generation modernization of the popular LAPACK library for accelerated multicore systemsTo generate the extreme level of parallelism needed for the efficient use of these systems, algorithms of interest are redesigned and then split into well-chosen computational tasks The task execution is scheduled over the computational components of a hybrid system of multicore CPUs with GPU accelerators and/or Xeon Phi coprocessors, using either static scheduling or light-weight runtime systems The use of light-weight runtime systems keeps scheduling overheads low, similar to static scheduling, while enabling the expression of parallelism through sequential-like code This simplifies the development effort and allows exploration of the unique strengths of the various hardware components Finally, we emphasize the development of innovative linear algebra algorithms using three technologies – mixed precision arithmetic, batched operations, and asynchronous iterations – that are currently of high interest for accelerated multicore systems
14 citations
References
More filters
Book•
01 Sep 2015TL;DR: The 5th edition as discussed by the authors contains all the things that made the earlier editions different from other textbooks, including integrating linear algebra and multivariable calculus, using effective algorithms to prove the main theorems (Newton's method and the implicit function theorem, for instance) and a new approach to both Riemann integration and Lebesgue integration.
Abstract: This 5th edition contains all the things that made the earlier editions different from other textbooks. Among others:
Integrating linear algebra and multivariable calculus
Using effective algorithms to prove the main theorems (Newton's method and the implicit function theorem, for instance)
A new approach to both Riemann integration and Lebesgue integration
Manifolds and a serious introduction to differential geometry
A new way of introducing differential forms and the exterior derivative.
There is also new material, in response to requests from computer science colleagues:
More big matrices! We included the Perron-Frobenius theorem, and its application to Google's PageRank algorithm
More singular values! We included a detailed proof of the singular value decomposition, and show how it applies to facial recognition: "how does Facebook apply names to pictures?"
13 citations
21 May 2012
TL;DR: A set of asynchronous iteration algorithms in CUDA developed and compared with a parallel implementation of synchronous relaxation methods on CPU-based systems shows the high potential of the asynchronous methods not only as a stand alone numerical solver for linear systems of equations fulfilling certain convergence conditions but more importantly as a smoother in multigrid methods.
Abstract: In this paper, we analyze the potential of asynchronous relaxation methods on Graphics Processing Units (GPUs). For this purpose, we developed a set of asynchronous iteration algorithms in CUDA and compared them with a parallel implementation of synchronous relaxation methods on CPU-based systems. For a set of test matrices taken from the University of Florida Matrix Collection we monitor the convergence behavior, the average iteration time and the total time-to-solution time. Analyzing the results, we observe that even for our most basic asynchronous relaxation scheme, despite its lower convergence rate compared to the Gauss-Seidel relaxation (that we expected), the asynchronous iteration running on GPUs is still able to provide solution approximations of certain accuracy in considerably shorter time than Gauss-Seidel running on CPUs. Hence, it overcompensates for the slower convergence by exploiting the scalability and the good fit of the asynchronous schemes for the highly parallel GPU architectures. Further, enhancing the most basic asynchronous approach with hybrid schemes -- using multiple iterations within the "sub domain" handled by a GPU thread block and Jacobi-like asynchronous updates across the "boundaries", subject to tuning various parameters -- we manage to not only recover the loss of global convergence but often accelerate convergence of up to two times (compared to the standard but difficult to parallelize Gauss-Seidel type of schemes), while keeping the execution time of a global iteration practically the same. This shows the high potential of the asynchronous methods not only as a stand alone numerical solver for linear systems of equations fulfilling certain convergence conditions but more importantly as a smoother in multigrid methods. Due to the explosion of parallelism in today's architecture designs, the significance and the need for asynchronous methods, as the ones described in this work, is expected to grow.
13 citations
01 Jan 2021
13 citations
Book•
01 Jan 2010
8 citations
17 Dec 2001
TL;DR: This article derives two new averaging algorithm to combine several approximations to the solution of a single linear system using the block method with multiple initial guesses and implements the new methods with ILU preconditioners on a parallel computer.
Abstract: Parallel Krylov (S-step and block) iterative methods for linear systems have been studied and implemented in the past. In this article we present a parallel Krylov method based on block s-step method for nonsymmetric linear systems. We derive two new averaging algorithm to combine several approximations to the solution of a single linear system using the block method with multiple initial guesses. We implement the new methods with ILU preconditioners on a parallel computer. We test the accuracy and present performance results.
5 citations
"A block-asynchronous relaxation met..." refers methods in this paper
...For example, when solving linear systems of equations with iterative methods like the Conjugate Gradient or GMRES, the parallelism is usually limited to the matrix-vector and the vector-vector operations (with synchronization required between them) [4] [5] [6]....
[...]