A comparison of three total variation based texture extraction models
Summary (2 min read)
1 Introduction
- Let f be an observed image that contains texture and/or noise.
- Texture is characterized as repeated and meaningful structure of small patterns.
- Noise is characterized as uncorrelated random patterns.
- The rest of an image, which is called cartoon, contains object hues and sharp edges .
1.1 The spaces BV and G
- In image processing, the space BV and the total variation semi-norm were first used by Rudin, Osher, and Fatemi [33] to remove noise from images.
- The ROF model is the precursor to a large number of image processing models having a similar form.
1.3 Second-order cone programming
- Since a one-dimensional second-order cone corresponds to a semi-infinite ray, SOCPs can accommodate nonnegative variables.
- In fact if all cones are onedimensional, then the above SOCP is just a standard form linear program.
- As is the case for linear programs, SOCPs can be solved in polynomial time by interior point methods.
- This is the approach that the authors take to solve the TV-based cartoon-texture decomposition models in this paper.
2.2.3 The Vese-Osher (VO) model
- This is equivalent to solving the residual-free version (45) below.
- The authors chose to solve the latter in their numerical tests because using a large λ in (44) makes it difficult to numerically solve its SOCP accurately.
3 Numerical results
- Similar artifacts can also be found in the results Figures 2 (h )-(j) of the VO model, but the differences are that the VO model generated u's that have a block-like structure and thus v's with more complicated patterns.
- In Figure 2 (h), most of the signal in the second and third section was extracted from u, leaving very little signal near the boundary of these signal parts.
- In short, the VO model performed like an approximation of Meyer's model but with certain features closer to those of the TV-L 1 model.
Example 2:
- This fingerprint has slightly inhomogeneous brightness because the background near the center of the finger is whiter than the rest.
- The authors believe that the inhomogeneity like this is not helpful to the recognition and comparison of fingerprints so should better be corrected.
- The authors can observe in Figures 4 (a ) and (b) that their cartoon parts are close to each other, but slightly different from the cartoon in Figure 4 (c).
- The VO and the TV-L 1 models gave us more satisfactory results than Meyer's model.
- Compared to the parameters used in the three models for decomposing noiseless images in Example 3, the parameters used in the Meyer and VO models in this set of tests were changed due to the increase in the G-norm of the texture/noise part v that resulted from adding noise.
4 Conclusion
- The authors have computationally studied three total variation based models with discrete inputs: the Meyer, VO, and TV-L 1 models.
- The authors tested these models using a variety of 1D sig- nals and 2D images to reveal their differences in decomposing inputs into their cartoon and oscillating/small-scale/texture parts.
- The Meyer model tends to capture the pattern of the oscillations in the input, which makes it well-suited to applications such as fingerprint image processing.
- On the other hand, the TV-L 1 model decomposes the input into two parts according to the geometric scales of the components in the input, independent of the signal intensities, one part containing large-scale components and the other containing smallscale ones.
- These results agree with those in [9] , which compares the ROF, Meyer, and TV-L 1 models.
Did you find this useful? Give us your feedback
Figures (6)

Fig. 5. Example 4 and 5, cartoon-texture decomposition: left halves - cartoon, right halves - texture/noise. 
Fig. 1. Example 1: 1D signal decomposition 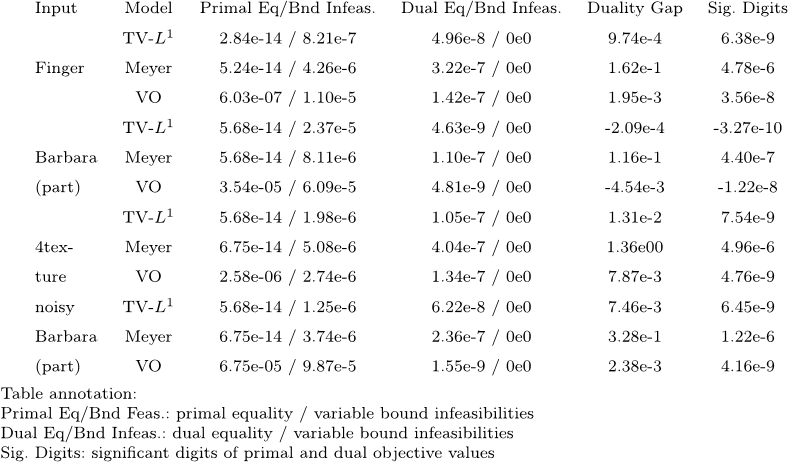
Table 1 Mosek termination measures 
Fig. 3. Inputs: (a) original 117×117 fingerprint, (b) original 512×512 Barbara, (c) a 256×256 part of original Barbara, (d) a 256×256 part of noisy Barbara (std.=20), (e) original 256× 256 4texture. 
Fig. 2. Example 1: 1D signal decomposition (continue) 
Fig. 4. Examples 2 and 3, cartoon-texture decomposition results: left halves - cartoon, right halves - texture.






Citations
15 citations
Cites background or methods from "A comparison of three total variati..."
...In [51], three regularization-based STD models, including L1-norm and G-norm, are formulated as a paradigm of second-order cone programs (SCOPs)....
[...]
...In a variational framework, the structural component u is generally obtained by optimizing the following objective function [1], [51]...
[...]
...Traditionally, to solve (6), diverse optimizers are required for different functional spaces [51]....
[...]
14 citations
Cites methods from "A comparison of three total variati..."
...Yin et al. proposed TVL1 model for decomposing an image into features of different scales (Yin et al., 2005, 2007), and compared several models (TV-L1, VO, Meyer) for image texture extraction in (Yin et al., 2007)....
[...]
14 citations
14 citations
Cites background from "A comparison of three total variati..."
...There has been an extensive line of papers (starting with [35]) modifying and interpreting Meyer’s models, andproposingminimization schemes: [2,3,19,24,33,36,39]....
[...]
12 citations
Cites background or methods from "A comparison of three total variati..."
...Since latent fingerprint is overlapped with different kinds of noisy patterns, the total variation (TV) image model, which minimized the total variation in image decomposition, was proposed to reduce the heavy noise for segmentation and enhancement [3], [12]....
[...]
...To simulate the varying backgrounds of latent images, we first decompose the latent images of NIST SD27 into texture and cartoon components by using the TV method [12]....
[...]
...We also compare the proposed fingerprint enhancement method with other methods in the literature [12], [18], [20], [28]....
[...]
...CMC curves of different enhancement methods with manual segmentation masks on NIST SD27: the proposed method with the loss functions of ‘SSIM + MSE’, ‘SSIM’ and ‘MSE’, DenseUNet method [20], Localized Dictionary method [28], multi-task method [18], and the TV method [12], which are denoted as “Proposed method with SSIM + MSE”,“Proposed method with SSIM”, “Proposed method with MSE”, “DenseUNet”, “Localized Dictionary”, “Multi-task” and “Texture”, respectively....
[...]
...To reduce the noise of latent image, we apply the Total Variance method [12] to decompose the latent image into the texture and cartoon components....
[...]
References
15,225 citations
"A comparison of three total variati..." refers methods in this paper
...Moreover, in [19] it is shown that each interior-point iteration takes O(n(3)) time and O(n(2)logn) bytes for solving an SOCP formulation of the Rudin–Osher–Fatemi model [33]....
[...]
...Moreover, in [19] it is shown that each interior-point iteration takes O(n3) time and O(n2logn) bytes for solving an SOCP formulation of the Rudin–Osher–Fatemi model [33]....
[...]
...In image processing, the space BV and the total variation semi-norm were first used by Rudin, Osher, and Fatemi [33] to remove noise from images....
[...]
3,377 citations
1,535 citations
"A comparison of three total variati..." refers background or methods in this paper
...When 1 < p <1, we use second-order cone formulations presented in [1]....
[...]
...With these definitions an SOCP can be written in the following form [1]:...
[...]
1,147 citations
"A comparison of three total variati..." refers background or methods in this paper
...G is the dual of the closed subspace BV of BV, where BV :1⁄4 fu 2 BV : jrf j 2 L(1)g [27]....
[...]
...Meyer’s model To extract cartoon u in the space BV and texture and/or noise v as an oscillating function, Meyer [27] proposed the following model:...
[...]
...Among the recent total variation-based cartoon-texture decomposition models, Meyer [27] and Haddad and Meyer [20] proposed using the G-norm defined above, Vese and Osher [35] approximated the G-norm by the div(L)-norm, Osher, Sole and Vese [32] proposed using the H (1)-norm, Lieu and Vese [26] proposed using the more general H -norm, and Le and Vese [24] and Garnett, Le, Meyer and Vese [18] proposed using the homogeneous Besov space _ Bp;q, 2 < s < 0, 1 6 p, q 61, extending Meyer’s _ B 1 1;1, to model the oscillation component of an image....
[...]
...This paper qualitatively compares three recently proposed models for signal/image texture extraction based on total variation minimization: the Meyer [27], Vese–Osher (VO) [35], and TV-L(1) [12,38,2–4,29–31] models....
[...]
...Meyer gave a few examples in [27], including the one shown at the end of next paragraph, illustrating the appropriateness of modeling oscillating patterns by functions in G....
[...]