
All figures (17)
 Figure 12: Signemes extracted from sentences
Figure 12: Signemes extracted from sentences Figure 3: Variations in relational distributions with motion. (a) Motion sequence. (b) Edge pixels from the skin color blobs. (c) Relational distributions constructed from the low level features (edge pixels) of the images in the motion sequence. The horizontal axis of the relational distribution represents the horizontal distance between the edge pixels and its vertical axis represents the vertical distance between edge pixels.
Figure 3: Variations in relational distributions with motion. (a) Motion sequence. (b) Edge pixels from the skin color blobs. (c) Relational distributions constructed from the low level features (edge pixels) of the images in the motion sequence. The horizontal axis of the relational distribution represents the horizontal distance between the edge pixels and its vertical axis represents the vertical distance between edge pixels. Figure 14: Extraction of the two most common patterns or signemes from the sentence ‘MY PASSPORT THERE STILL GOOD THERE’.
Figure 14: Extraction of the two most common patterns or signemes from the sentence ‘MY PASSPORT THERE STILL GOOD THERE’. Figure 13: Extraction of the two most common patterns or signemes from the sentence ‘BAGGAGE THERE NOT MINE THERE’.
Figure 13: Extraction of the two most common patterns or signemes from the sentence ‘BAGGAGE THERE NOT MINE THERE’.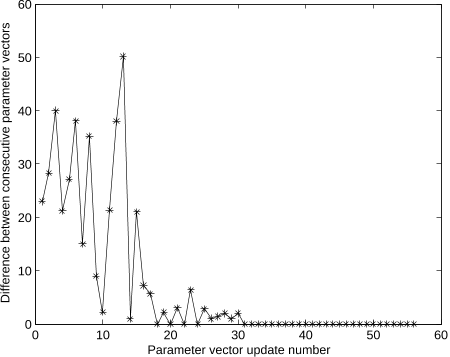 Figure 7: Convergence of values of the parameter set. The above plot shows the norm of the difference between two consecutive parameter vectors representing the set of starting points and widths of the common subsequence in the given set of sequences. It shows the typical convergence with a given initialization vector. ICM is repeated with multiple initializations and the most frequently occurring solution is considered as the final solution.
Figure 7: Convergence of values of the parameter set. The above plot shows the norm of the difference between two consecutive parameter vectors representing the set of starting points and widths of the common subsequence in the given set of sequences. It shows the typical convergence with a given initialization vector. ICM is repeated with multiple initializations and the most frequently occurring solution is considered as the final solution. Figure 1: Movement epenthesis in sign language sentences. Frames corresponding to the common sign ‘BUY’ are marked in red. Signs adjacent to BUY are marked in magenta. Frames between marked frames represent movement epenthesis that is, the transition between signs. Note that the sign itself is also affected by having different signs preceding or following it.
Figure 1: Movement epenthesis in sign language sentences. Frames corresponding to the common sign ‘BUY’ are marked in red. Signs adjacent to BUY are marked in magenta. Frames between marked frames represent movement epenthesis that is, the transition between signs. Note that the sign itself is also affected by having different signs preceding or following it. Figure 9: The first dimension of the video sequences containing a common sign ‘DEPART’. The sequences are indicated by the dotted curves and the solid lines on each of them indicate the common pattern or signeme. The odd columns represent the ground truth and the even columns show the results.
Figure 9: The first dimension of the video sequences containing a common sign ‘DEPART’. The sequences are indicated by the dotted curves and the solid lines on each of them indicate the common pattern or signeme. The odd columns represent the ground truth and the even columns show the results. Table 2: Localization Performance
Table 2: Localization Performance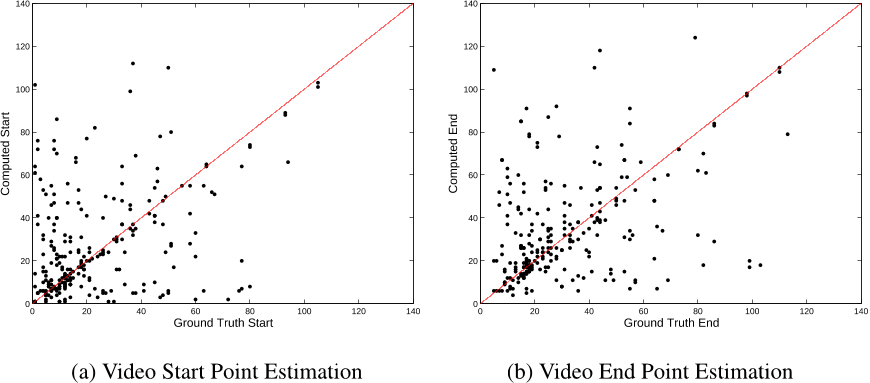 Figure 15: Extraction of the most common patterns or signemes from the ‘mixed’ sentence groups. The closer the points are to the diagonal, the closer the result is to the ground truth.
Figure 15: Extraction of the most common patterns or signemes from the ‘mixed’ sentence groups. The closer the points are to the diagonal, the closer the result is to the ground truth. Figure 6: Convergence of the conditional probability density f (θi|θ(i)) for sentences S1...S6 from a given set of sentences S1...S14. The brighter regions represent a higher probability value. The vertical axis in the probabilities represents the starting locations and the horizontal axis represents the possible widths. Note that the probabilities are spread out in the first iteration and it slowly converges to a particular starting location. They are still spread across the horizontal (width) axis because we vary the width only in a small range that is decided based on the amount of motion present in the sign.
Figure 6: Convergence of the conditional probability density f (θi|θ(i)) for sentences S1...S6 from a given set of sentences S1...S14. The brighter regions represent a higher probability value. The vertical axis in the probabilities represents the starting locations and the horizontal axis represents the possible widths. Note that the probabilities are spread out in the first iteration and it slowly converges to a particular starting location. They are still spread across the horizontal (width) axis because we vary the width only in a small range that is decided based on the amount of motion present in the sign. Figure 10: Extraction of the most common patterns or signemes from the ‘pure’ sentence groups. The closer the points are to the diagonal, the closer the result is to the ground truth.
Figure 10: Extraction of the most common patterns or signemes from the ‘pure’ sentence groups. The closer the points are to the diagonal, the closer the result is to the ground truth. Figure 5: Sequential update of the parameter values using ICM. (a), (b) and (c) respectively show the parameter updates in the first sentence, the ith and the nth sentences. In the rth iteration, the parameters of the common sign in ith sentence is computed based on the parameter values of the previous (i− 1) sentences obtained in the same iteration, and those of the (i+1)th to nth sentences obtained in the previous, that is, the (r−1)th iteration.
Figure 5: Sequential update of the parameter values using ICM. (a), (b) and (c) respectively show the parameter updates in the first sentence, the ith and the nth sentences. In the rth iteration, the parameters of the common sign in ith sentence is computed based on the parameter values of the previous (i− 1) sentences obtained in the same iteration, and those of the (i+1)th to nth sentences obtained in the previous, that is, the (r−1)th iteration. Figure 16: Start Offset vs. End Offset of Localized Signs
Figure 16: Start Offset vs. End Offset of Localized Signs Table 1: Notations
Table 1: Notations Figure 11: Signemes extracted from sentences
Figure 11: Signemes extracted from sentences Figure 2: Overview of our approach. Each of the n sentences is represented as a sequence in the Space of Relational Distributions, and common patterns are extracted using iterated conditional modes (ICM). The parameter set {a1,w1, ...an,wn} is initialized using uniform random sampling and the conditional density corresponding to each sentence is updated in a sequential manner.
Figure 2: Overview of our approach. Each of the n sentences is represented as a sequence in the Space of Relational Distributions, and common patterns are extracted using iterated conditional modes (ICM). The parameter set {a1,w1, ...an,wn} is initialized using uniform random sampling and the conditional density corresponding to each sentence is updated in a sequential manner. Figure 8: Histograms showing the start and end locations of signs extracted from 14 different sen-
Figure 8: Histograms showing the start and end locations of signs extracted from 14 different sen-
















