



Similar to how Charlie Chaplin's slapstick antics, bowler hat, and mustache made him well-known throughout the world, metadata promotes your research article, and boosts the author's and journals' public recognition. In simpler words, metadata helps your research articles reach every corner of the web and ensures easier and faster dissemination of your research work.
Additionally, metadata makes articles easier to find in scholarly indexes, online databases, and search engines. Due to the quick distribution of research works, it aids users or readers in finding pertinent resources and helps researchers get cited. Thus, metadata is the Holy Grail of scholarly communication to improve journal accessibility.
This article will provide you with a thorough understanding of metadata. We will go over the definition of metadata, different types of metadata, schemas, and their applications in scientific literature.
Introduction to Metadata
Until the 1980s, even before catalogs were converted into digital databases, metadata was used only in the library catalog. But, in the early 2000s, as data and information storage ascended, metadata standards were created to describe online data or attributes.
The metadata standard is a requirement that forms a common understanding of the structure and semantics of the data. So, there was a need to define several data standards to attain this understanding, and that's when metadata came into existence. Metadata’s primary purpose is to determine and provide information about data, including its characteristics and attributes in machine and human-readable formats.
Thus, metadata has manifold purposes, including the organization of electronic documents, providing information about data, issuing digital identification, storing, archiving, and preserving journal articles.
What is Metadata?
Metadata is defined as "the data that provides basic information about the digital objects of the article that aids search engines and scientific databases in quickly discovering the research article.” In simpler terms, it is any data that provides information about other data. Metadata fields can be anything that lands you on the intended research work; be it the author name, title, keywords, licensing, ISSN (International Standard Serial Number - a unique number assigned to journals), volume, page numbers, authors ORCID iDs, and other standard identifiers. Besides, it is not restrictive to an object; rather, it can be anything relevant to the resource.
Also, there are different types of metadata available to enrich the dissemination of research work at various stages of research communication. Let’s look at them.
Types of Metadata

- Structural Metadata: It shows how the digital objects are arranged for smooth navigation and presentation of the data in an online database. Structural metadata helps to describe the type, versions, structures, linking, and object relationship.
Example: Page number, sections, table of contents, and more. - Descriptive Metadata: It is the most widely used form that provides data about the content of the digital object. Descriptive Metadata is used to discover and search the journal articles to access the data through the description.
Example: Title, abstract, author, keyword, and more. - Administrative Metadata: It denotes the technical information of the digital object such as usage rights, licensing, IP (Intellectual Property) rights, etc. Administrative metadata is used for article management and preservation purposes.
Example: Version no., archive date, date of creation, the person who created it, etc.
All these metadata facilitate the exchange of data between the stakeholders of the scientific community (authors, publishers, and online service providers). Consequently, they rescue your journal articles from getting buried in the content or research articles stack by making them searchable on search engines and online databases. Check out this article to get more understanding on why journal publishers use rich Metadata for enhanced visibility?
Making our articles discoverable is great, but how is metadata created and submitted to repositories?
Let's unveil!
How to create Metadata for Journal Articles
An Introduction to DOI (Digital Object Identifier)

Technically, metadata is created by authors and publishers, and the steps to create are as follows:
- First, they document the essential elements or fields of the research work
- Then, they create a DTD (Document Type Definition) of the article, which includes the structured representation of the article.
Example:
<title></title>
<ISSN></ISSN>
<author></author> - Furthermore, the data or the descriptive content of the article are incorporated into the DTD structure.
Example:
<author>H. M. Jacob</author> - Now, the publishers develop the web pages for this DTD structure without modifying the content. And that's how the metadata is created.
- Later, they are submitted to the DOI registration agency to register the article to get a unique identifier.
To scale up the reach and impact of the article, publishers and other academic stakeholders are increasingly linking the metadata to DOI.
What is DOI?
It was challenging to link articles together and locate them on the search results page in the late 1990s due to the abundance of scientific literature. In order to make it simple to link citations to the full text of articles or their abstracts, PILA (Publishers International Linking Association Inc.) created Crossref in January 2000. It is an official registration agency of the International DOI Foundation. Now to answer the most important question “What is DOI ?”. Digital object identifiers are the unique alphanumeric string assigned to each research work used to identify the article and provide a permanent web address. DOI acts as the digital fingerprint where each article gets a unique identification number which provides information about the article and helps to cite the article throughout its lifespan. Even if the web address (URL) changes, the DOI will remain the same irrespective of the location information. Also, if the authors circulate different versions of the article, the readers can still find the original one using DOI.
Why should you use DOI?

As described by the scholar Péter Jacsó, "metadata mega mess" articulates the search result discrepancies because of the similar keyword search.
Didn't get it?
I'll make that easier for you; when you search for an article on Google or Google scholar using a keyword or author name, or title of the article, there are chances the result might include wrong or irrelevant articles because of the common names, keywords, and titles found by its algorithm. In addition, it might increase the citations of other articles that resulted in your search instead of the intended or original article piece. Hence the articles must be linked to DOI to reduce the risk of getting lost in the "big mess."
As a unique identifier, DOI makes the journal articles easily discoverable anywhere anytime with a simple click on the link. Moreover, when DOI is incorporated in the citation, it becomes the permanent location for the article cited. Similarly, when attached to the article, it helps a swift online discovery as it is machine-readable.
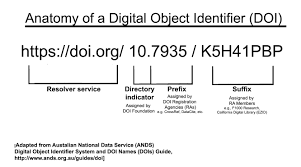
Furthermore, you can get the DOIs from any DOI registration agencies (Crossref - widely used). You have to submit the rich metadata to Crossref in a machine-readable format to store the article information with DOI alongside. Because the search engines like Google and Google scholar mainly rely on machine-readable data to make them indexable and searchable.
Pro-Tip: If you are keen, refer to this step-by-step guide to learn how to submit the metadata to Crossref.
Now that we have learned how to create metadata and its linking with DOI to the journal article and DOI’s significance. Let's uncover its benefits.
What are the benefits of Metadata in scholarly publishing?

Metadata provides the vital infrastructure to bind the scientific community together. Also, it is bridging the gap of the publishing industry to ensure that scholarly works and advanced world are interconnected without causing any data or information loss. Similarly, using metadata in academic publishing has got multiple advantages, and the three most essential benefits include:
- Use metadata for better classification and discoverability
- Use metadata for open access publishing
- Use metadata as a gratuity for publishers and authors
1. For better classification and discoverability
To foster the interoperability of data between digital systems, the evolution of bibliographical standards took place. They inherited the referencing and cataloging standard that existed before digitalization where every document had to be registered with a bibliographical card, namely title, author, page number, volume, etc. Similarly, metadata schemas are created to transform this criterion into a programmed format and make the indexing and discovery process more accessible.
In 1995, DCMI (Dublin Core Metadata Initiative), an international working professional group of different disciplines, established generic metadata to represent digital objects (You can find its details in the following section). So far, it is the most commonly used schema. Likewise, there are many other standards available based on disciplines. However, let's discuss the most significant ones here:
Briefing About Metadata Schema
A schema is the metadata elements grouped into sets and created for a specific objective (specific domain or specific information). Therefore, each of the metadata elements has different metadata schemas, respectively. So, for every element, the name and semantics are designed.
The most common types of schemas used are:
- Dublin Core Metadata Element Set (DCMES) or DCMI: It is the best-known metadata schema for discovering resources. It consists of 15 vocabulary terms used to find the articles in online databases. Several National and International standards organizations endorse it.
- MARC (Machine Readable Cataloging): They are responsible for communicating bibliographic and related information in a machine-readable format.
- MODS (Metadata Object Description Schema): It is richer than DCMES, also used as a schema for the bibliography set. It can be used alone or along with other formats.
- PREMIS (Preservation Metadata Implementation Strategies): It is used to preserve the metadata for long-term usability
- VRA Core (Visual Resources Association Core): It is the standardized data for the description of visual and audio files.
- EAD (Encoded Archival Description): It uses XML in manuscripts and archival repositories to encode archival finding aids.
- METS (Metadata Encoding & Transmission Standard): It uses an XML schema language to encode structural, descriptive, and administrative metadata.
- PBCore (Public Broadcasting Core): A standard schema for describing data sharing tools, audiovisual, etc.
- TEI (Text Encoding Initiative): A consortium for developing and maintaining text representation standards in digital form.
2. For open access publishing
Open Archive Initiative was developed to promote open access by creating interoperability standards with the implementation of OAI-PMH (Open Archive Initiative Protocol Metadata Harvesting). It encourages spontaneous data exchange, irrespective of the file size between the services providers and the archives or the repositories. This protocol prompts the articles to collect the metadata descriptions of open access repositories like PubMed, ArXiv and thus provide hassle-free access to the online databases.
3. As a gratuity for publishers and authors
According to the industry leaders' survey reports in 2017, over 90% of the publishers are willing to invest in metadata despite the budget constraint. It has been given the most significant importance in research dissemination. The publisher's inclination towards metadata investment is because of the increased sales of journal articles associated with quality metadata and the implementation of JATS XML to model journal articles.

Since the JATS XML has become the de-facto medium in academic publishing, its extensive metadata storage support has made the publishers contemplate them.
JATS XML is machine-readable and readily searchable; when the articles are published in JATS format, the files can be easily accessed, read, and indexed by the academic search engines. The metadata travels along with an article wherever it is published, which is excellent for semantic data exchange between all the publishing industry stakeholders.
For authors, JATS XML helps in getting higher citations and readership. In turn, it helps to increase the journal's impact factor and quality. And its extensive storage capacity to record data is the show-stealer here. Hence, it is recommended to convert the files into JATS XML before publishing. For a better understanding of JATS XML, do check out this blog.
If the conversion part seems tricky, you can rely on automated tools or software like SciSpace (Formerly Typeset) for a one-click conversion without any technical difficulties. Also, it offers multiple features for the benefit of universities, researchers, and publishers.
Wrapping Up
By looking at the headway of the academic industry, it is evident that metadata will play a prominent role in dilating the reach of research works. However, its creation and maintenance are directly proportional to the investment, time, and efforts regardless of the type of schema used. Despite the growth of open initiatives and well-established international metadata standards, publishers and authors are actively propagating them to promote interoperability.
These initiatives and standards are stewarding their management in scholarly communications. Thus, metadata is the central dogma of scientific publishing that takes care of research dissemination by simplifying the discoverability and accessibility of journal articles.
In view of your interest in simplifying research workflows, we suggest you take a look at SciSpace discover. The portal lets you perform all your research writing, including literature searches, in one place.

SciSpace provides researchers, universities, and publishers with all the tools they need. Our comprehensive research repository features more than 200 million research papers from multiple disciplines with SEO-optimized abstracts, a publicly visible profile to highlight your expertise, a specially-built collaborative text editor, 20,000+ journal templates, and more.

Explore More: Resources for Publishers
- PDF to JATS XML Conversion — Why it’s important for an Academic Publisher
- Top 4 MS-Word (Docx) to JATS XML Converters
- JATS XML: Everything a Publisher Needs to Know
- How JATS XML Can Positively Impact Publishers




